
Today we are proud to announce that we have completed training of Inflection-2, the best model in the world for its compute class and the second most capable LLM in the world today.
Our mission at Inflection is to create a personal AI for everyone. Just a few months ago, we announced Inflection-1 — a best-in-class language model that currently powers Pi. Our new model, Inflection-2, is substantially more capable than Inflection-1, demonstrating much improved factual knowledge, better stylistic control, and dramatically improved reasoning.
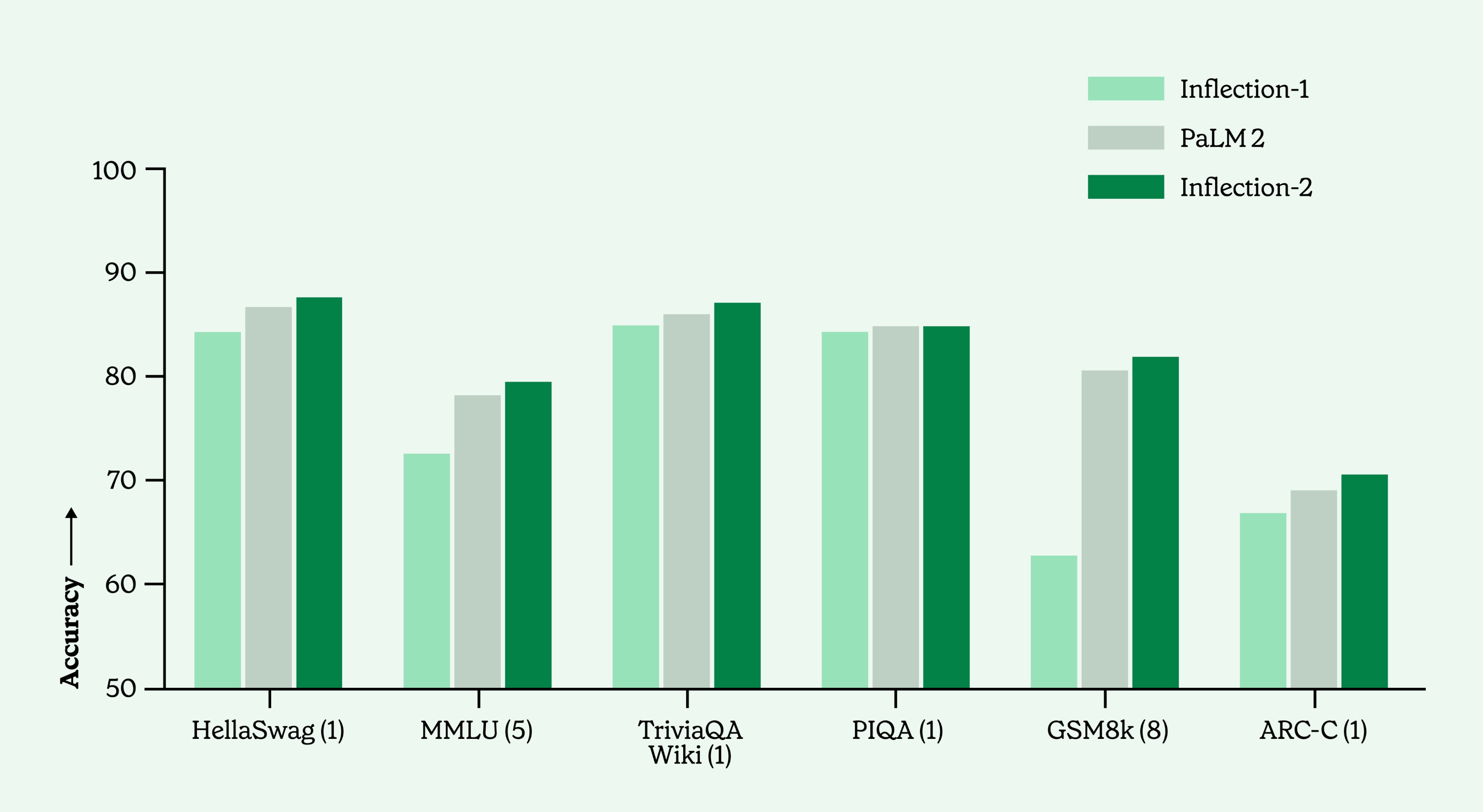
Figure 1: Comparison of Inflection-1, Google’s PaLM 2-Large, and Inflection-2 across a range of commonly used academic benchmarks. (N-shots in parentheses)
Inflection-2 was trained on 5,000 NVIDIA H100 GPUs in fp8 mixed precision for ~10²⁵ FLOPs. This puts it into the same training compute class as Google’s flagship PaLM 2 Large model, which Inflection-2 outperforms on the majority of the standard AI performance benchmarks, including the well known MMLU, TriviaQA, HellaSwag & GSM8k.
Designed with serving efficiency in mind, Inflection-2 will soon be powering Pi. Thanks to a transition from A100 to H100 GPUs, as well as our highly optimized inference implementation, we managed to reduce the cost and increase the speed of serving vs. Inflection-1 despite Inflection-2 being multiple times larger.
This is a big milestone on our path towards building a personal AI for everyone, and we’re excited about the new capabilities that Inflection-2 will enable in Pi. As our scaling journey continues, we are already looking forward to training even larger models on the full capacity of our 22,000 GPU cluster. Stay tuned!
Training very large models demands a special level of care and attention to matters of safety, security, and trustworthiness. We take these responsibilities seriously at Inflection, and our safety team continues to ensure that these models are rigorously evaluated and integrate best-in-class approaches to alignment. We were the first to sign up to the White House’s July 2023 voluntary commitments, and continue to support efforts to create global alignment and governance mechanisms for this critical technology.
We thank our partners NVIDIA, Microsoft, and CoreWeave for their collaboration and support in building our AI cluster that made the training of Inflection-1 and Inflection-2 possible.
Results
It is important to benchmark our models against the state of the art to validate our progress. The results below are from our pre-trained model and do not involve chain-of-thought prompting, except for GSM8k. Before Inflection-2 is released on Pi, it will undergo a series of alignment steps to become a helpful and safe personal AI.We show Inflection-2’s performance on a wide range of benchmarks, comparing it to Inflection-1 and the most powerful external models LLaMA-2, Grok-1, PaLM-2, Claude-2 and GPT-4. We show the number of shots (examples given to the model) in parenthesis. If a result was not reported by the developers of a model, we show a ‘-’. Unless noted, all evaluations are reported in the same format as in the Inflection-1 tech memo.We evaluate Inflection-2 on MMLU (5-shot), a diverse set of tasks ranging from high school to professional level. Inflection-2 is the most performant model outside of GPT-4, even outperforming Claude 2 with chain-of-thought reasoning.

Table 1: We show results on the MMLU benchmark. All results are 5-shot without Chain-of-Thought except for Claude 2 which only reports values with CoT reasoning.Next, we show results on a wide set of benchmarks ranging from common sense to scientific question answering.

Table 2: We show results on a variety of benchmarks, primarily in the 0-shot and 1-shot setting. Inflection-2 reaches 89.0 on HellaSwag 10-shot compared to GPT-4’s 95.3, though the results are not directly comparable as GPT-4 states their “results are computed on a privately held secret holdout [...]”.Below, we show results on TriviaQA and NaturalQuestions, two question answering tasks. We report 1-shot results similar to PaLM 2 and LLaMA 2.

Table 3: Results on question answering tasks. We show Natural Questions and two splits of Trivia QA.Code and mathematical reasoning were not an explicit focus in the training of Inflection-2. Nonetheless, Inflection-2 performs very well on benchmarks covering both subjects. For coding performance, we compare to the strongest model presented in the PaLM 2 Technical Report which is PaLM 2-S*, a variant of PaLM 2 which has been specifically fine-tuned for coding performance.

Table 4: Results on math and coding benchmarks. Whilst our primary goal for Inflection-2 was not to optimize for these coding abilities, we see strong performance on both from our pre-trained model. It’s possible to further enhance our model’s coding capabilities by fine-tuning on a code-heavy dataset.
Come run with us as we scale 100x from here!
We are a small team that pushes the limits of scale in pursuit of our mission to create a personal AI for everyone. If you are interested in training state-of-the-art foundation models, aligning them with human preferences, making them more safe, and co-designing a new generation of products around them, come join us on our mission.
If you compare to Inflection-2 in a publication, please cite as:
@misc{inflection-2, author = {{Inflection AI}}, title = {Inflection-2}, url = {https://inflection.ai/inflection-2}, year = {2023} }


